Salary and more-Data Scientist, Analyst, Engineer
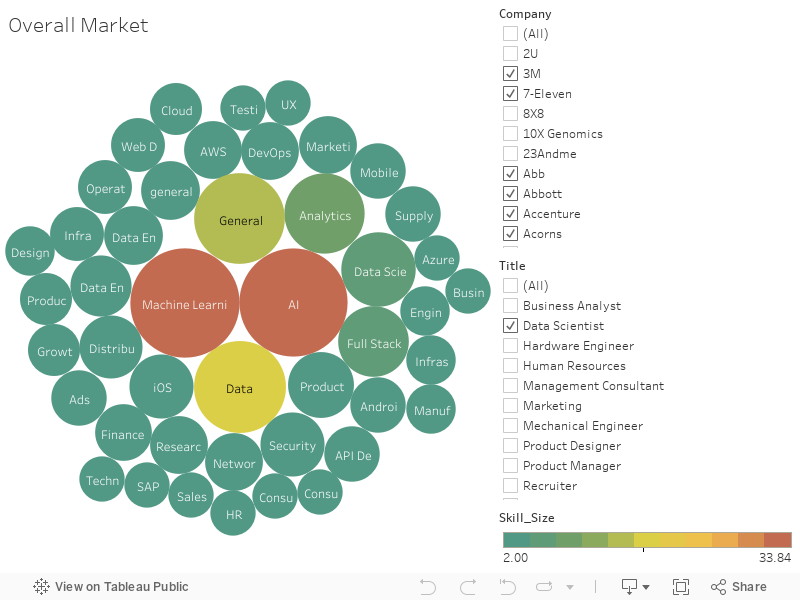
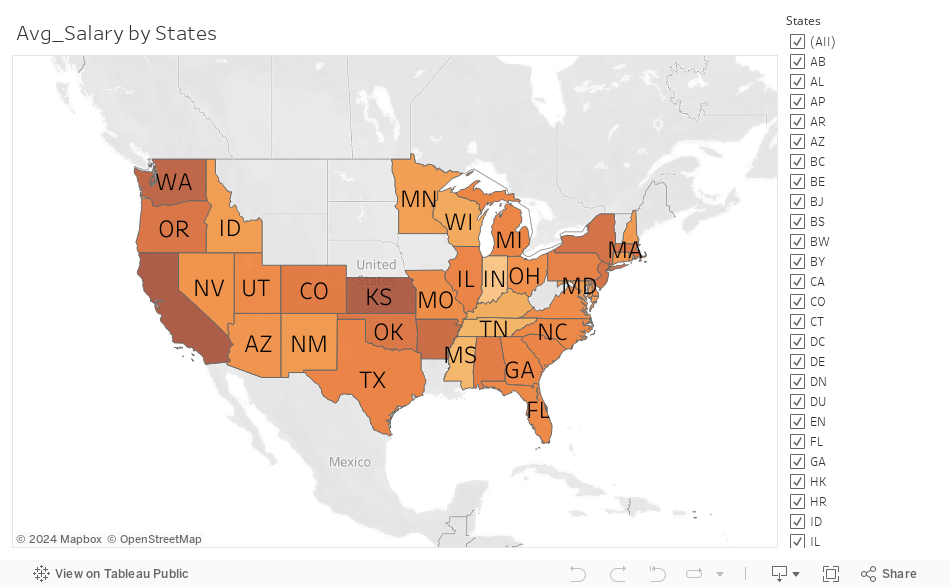
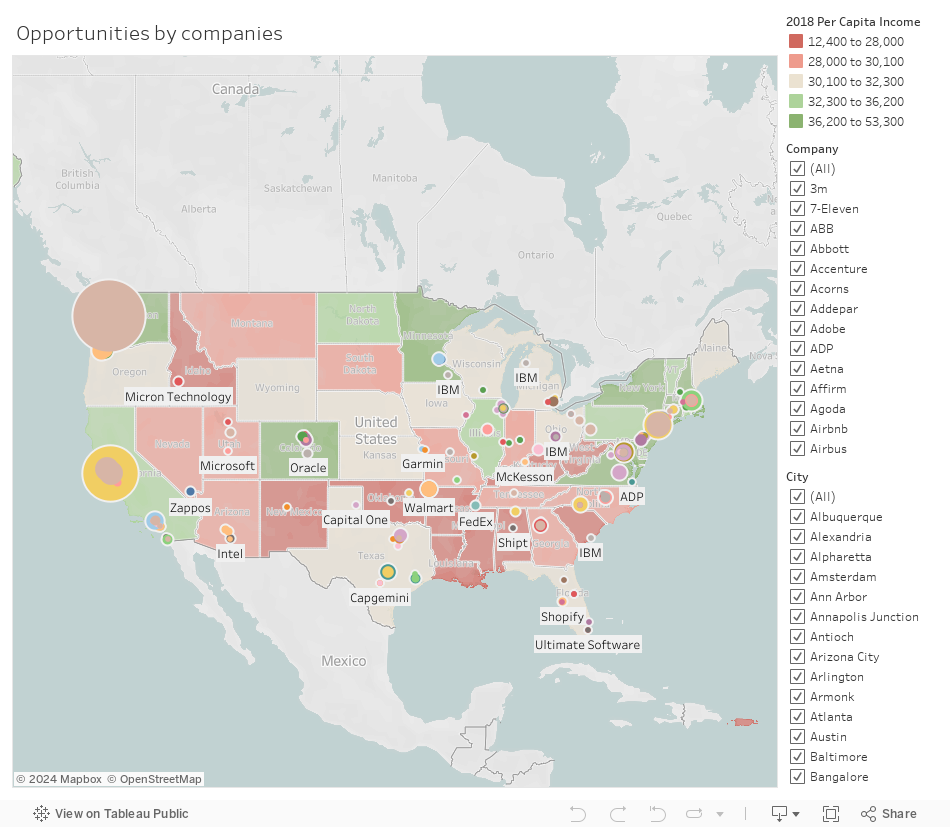
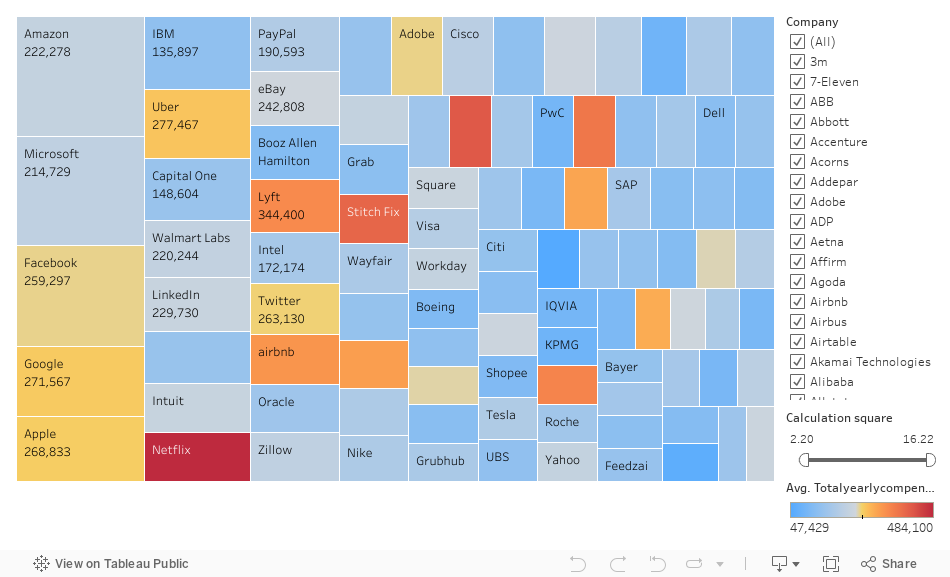
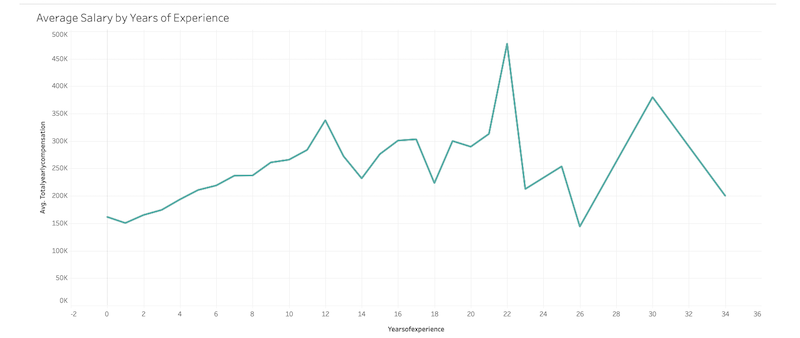
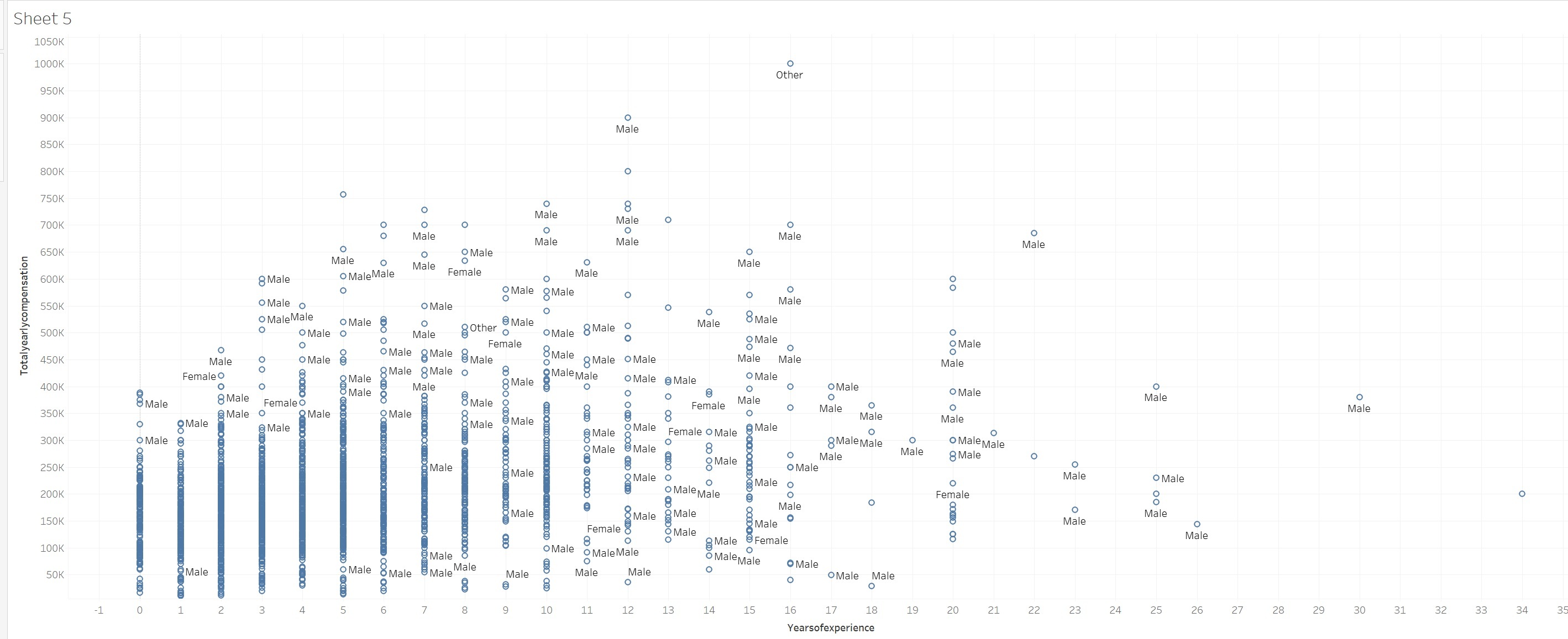
This dataset has 62,000 salary records from top companies. It contains information such as company, location, education level, compensation (base salary, bonus, stock grants), race, and other details.